Depth Search for Research Nerds 🤓
GitHub Check out the code on GitHubDoes your browser often look like this?
 For me, often this was a consequence of me reading one important article and opening up many links within it in the background.
For me, often this was a consequence of me reading one important article and opening up many links within it in the background.
I wondered if there is any way for me to know which links are important (Eg which wikipedia references are significant) without having to open them up. So basically a way of doing a Ctrl + F through all the links in a page, and not just the page itself. Not that hard right?
And why stop there. Why not go through all the links within those pages too!? Granted, that’s more than what laymen like me might require, but I imagined it to have actual value in the hands of journalists and researchers and academics (who have to go through maaany citations of many papers)
This is how I’ll be referring to it:
- Depth=0 : Regular current (home) page search
- Depth=1 : Search through all pages linked in the home page
- Depth=2 : Search through all pages linked in the all the pages that are linked to the home page
- …
Of course, the first place I go for such tools is the Chrome Web Store (where I have found many amazing extensions. I might make a list of them too someday too). I found this, which kiiind of solves it, but not really.
I wanted this tool to be a browser extension, because that’s the only practical way someone is going to use it. Hardly anyone is going to run a python script for a URL that interests them.
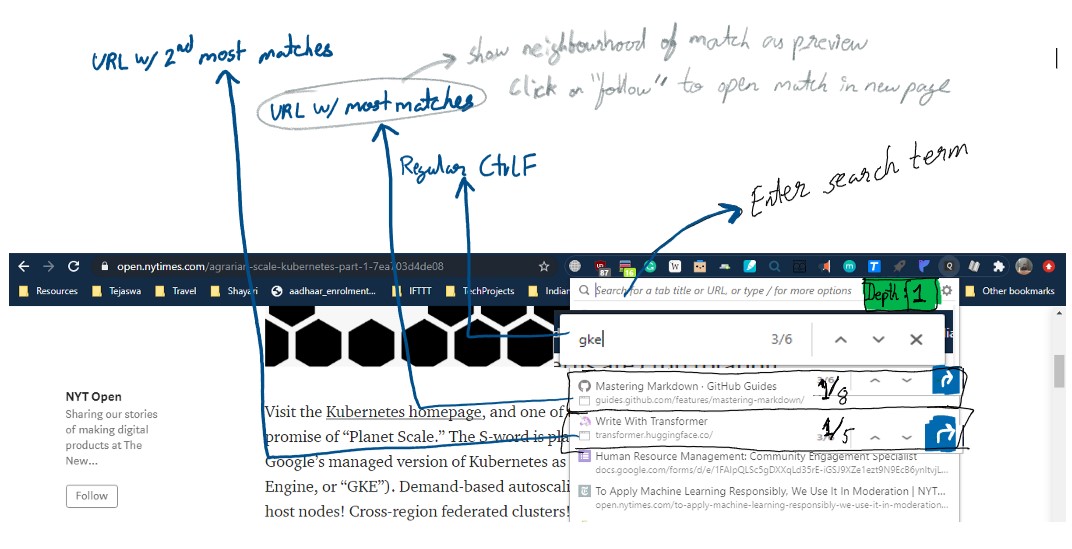
I was aware that it was going to have exponential time complexity (O(cn), but I thought that the operations itself (text search) is not that expensive (Boy was I wrong), and almost no one will really need a depth>2
I started a tutorial on making extensions, but I quickly realised that I would not be able to do as good a job as needed in Javascript. So I got a friend onboard who said he would do the JS stuff if I did the exploration and came up with the logic.
And spoiler alert, he could never get to the chrome extension as the exploration itself threw up concerns.
It was never going to be a straightforward recursive because almost inevitably there are links at the header and footer and even advertisements that are unnecessary. I did my analysis using Beautiful Soup. Maybe I should have used Scrapy or some other tool?
My observations on all the cases I encountered:
-
There are always repeated URLs in a page. Mostly about the website itself (rather than the content). Eg: Subscribe, Links to latest articles, link to twitter/app store. These accounted for 10-30% of links, so that was a good thing to catch.
-
Secondly, its not enough to remove repetitions on each page, but we also need to remove repetitions across all pages. Eg: If my depth=0 is a NYT article, then a lot of links in it will be for other NYT articles that all have the same header (home page, trending, business, tech..) and footer (about us, legal, careers..). So I made sure the article I was about to search has not already been searched.
-
Probably the biggest improvement (order of magnitude) in performance was pretty simple actually. I will ‘dive’ only into those articles that have non zero articles. Eg. If user has requested depth=2, and only 56/105 links at depth=1 actually have any matches. Then only those 56 will be searched instead of all 105 as part of depth=2.
-
Advertisements were not really a problem, for some reason they were not even showing up in my code’s extracted URLs. Maybe has something to do with the way they are rendered on front end? Idk. I still looked into some solutions and would have probably come up with something using a mature list and implemented using bloom filters.
-
I was using a regex to pick stuff that looks like a URL. i.e starts with http, www etc.. But I later caught some links that were being left out
 So I made sure to catch them too.
So I made sure to catch them too.
Actual use of all this?
If you don’t mind, you can use this a locally or in Colab as a notebook. But as to the question of putting it in a browser extension, I am not sure how that will work.
Since even Depth=1 can take a couple of minutes*  (when run through an IPython kernel on a 1.6Ghz 8GBRAM Windows 10 machine), its probably going to be even slower running as a chrome extension (If you know more about this, please reach out to me).
(when run through an IPython kernel on a 1.6Ghz 8GBRAM Windows 10 machine), its probably going to be even slower running as a chrome extension (If you know more about this, please reach out to me).
So maybe server-side processing is the way to go rather than client side. Then I might be able to use better machines from GCE too. ^
Misc:
Additionally, bs4 is compatible with PDFs too, and as part of an academic solution (for research papers) this could be extended to PDFs too and not just webpages
^ If getting count of links is not too expensive, we can do it and accordingly do server side processing only for requests that we know are going to take too long, and also set wait time expectation for the user.
* I definitely should be doing some parallel threading for the links since this serial processing is majorly slowing it down.
Check out my other projects!🌟
I'd love to know what you thought of this